Is more data always better?
With the increasing availability of experimental and observational data, there is a substantial accumulation of information within scientific research. This Big Data is used to extract valuable insights and patterns from extensive and intricate datasets, which facilitates data-driven decision-making by providing timely and precise information. However, as the volume of data continues to grow exponentially, concerns arise regarding its potential pitfalls. Xiaoyao Han explores how the accumulation of data enriches our scientific understanding.
By Xiaoyao Han, PhD student at UG/Campus Fryslân
My PhD is about the added value of Big Data and explores how the accumulation of data enriches our scientific understanding. In my project, I aim to find answers to the question of how we value the size of data from a scientific perspective, and how we can develop a framework for it through interdisciplinary research in order to contribute to a better understanding of the value of data in science.

What is Big Data and where does it come from?
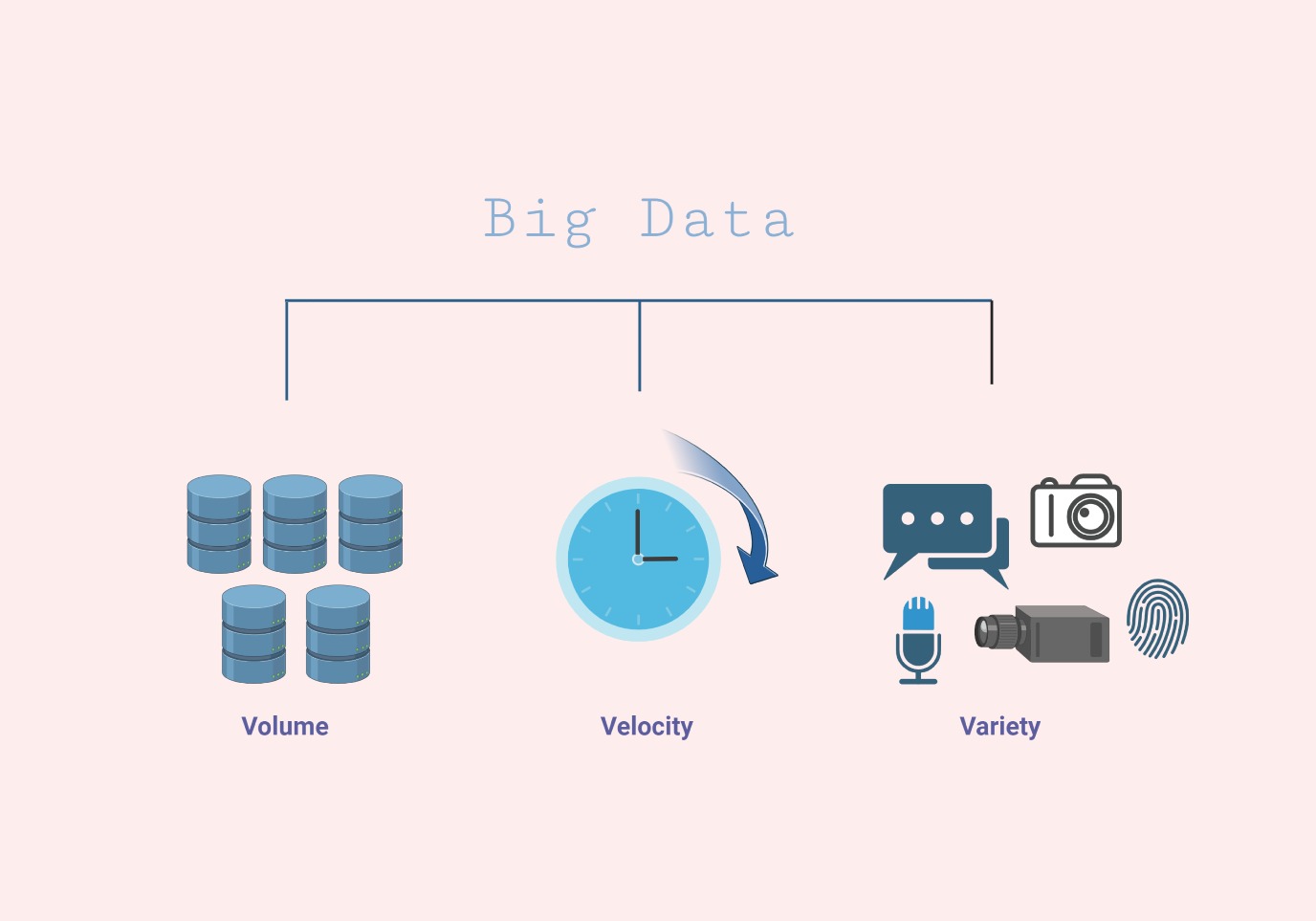
In short, when data becomes too vast to manage effectively, it is classified as Big Data. There are various definitions of Big Data, however there is no official consensus on it. The most common definition assumes three dimensions: volume, velocity, and variety. Volume refers to the large amount of data. It is generally measured in exabytes (1018), zettabytes (1021), and yottabytes (1024). Velocity reflects the very high speed at which data can be generated. With an average of 500 million tweets per day, Twitter is a great example of this speed. Variety refers to the diverse types and formats of data that are generated and collected. Unlike traditional data sources that primarily consist of structured data stored in relational databases, Big Data encompasses a wide range of data types including structured databases, texts, images, and videos. In all three dimensions, Big Data is indeed big, and it is only increasing.
Big Data can be found across various scientific fields. In astronomy, vast amounts of data are collected by capturing images and spectra of celestial objects using telescopes. Similarly, in bioinformatics, DNA sequencing generates huge datasets. In ecology, Big Data is derived from the use of remote sensing technology to monitor and analyze vegetation dynamics at large spatial and temporal scales. Managing, storing, and analyzing such large datasets requires advanced computational infrastructure and bioinformatic tools. Researchers use innovative algorithms and techniques to effectively analyze these large-scale datasets.
Big Data allows researchers to analyze extensive datasets from multiple sources and to gain a comprehensive understanding of the various factors in a situation or problem. Moreover, by using machine learning and AI models, research can assist organizations in making smart decisions based on data instead of just relying on intuition or past experiences. While Big Data offers many insights, it also raises critical questions about its scientific validity. To what extent does the accumulation of data enhance our understanding of complex scientific phenomena and facilitate informed decision-making in various fields? What implications arise from the pursuit of more data collection and the extensive use of these datasets in science?
Is bigger better?
The general belief that ‘bigger is better’ has fueled enthusiasm for Big Data, with its proponents praising its potential for transformative research. Traditionally, researchers develop hypotheses based on existing theories and conduct experiments to test these hypotheses. With the advent of Big Data, researchers can now uncover hidden patterns, associations, correlations, and trends within large datasets that may not have been evident using traditional hypothesis-driven methods. In healthcare, for instance, Big Data allows researchers to delve into extensive patient datasets, uncovering correlations between medical conditions, treatments, and outcomes to reveal more effective preventive measures. Similarly, in transportation systems, Big Data correlates traffic patterns, weather conditions, and vehicle movement data to optimize the traffic flow and improve public transportation routes. Climate scientists use Big Data to examine massive datasets from satellites, weather stations, and environmental sensors. By correlating different climate variables such as temperature, precipitation, and greenhouse gas concentrations, researchers gain insights into climate change trends and are able to predict extreme weather events.
However, there are also significant concerns about the scientific validity of Big Data. Critics argue that the emphasis on correlation over causation undermines the purpose of Big Data research. Without a solid theoretical foundation, correlations could be misinterpreted or misleading, which could lead to incorrect conclusions. For example, in healthcare, there are sometimes big differences between studies done on individual patients and those based on large databases. This can make it difficult to trust the results, especially when trying to compare different studies or when trying to adjust the results based on factors such as age or health problems. Ethical considerations for Big Data are also raised, especially with regard to privacy, consent, and algorithmic bias. Research on the coronavirus, for example, raises ethical issues surrounding privacy, the use of personal data to limit the pandemic spread, and the need for security to protect data from being overused by technology. As data collection only increases, questions arise about the ownership and control over information, and its role in shaping decision-making.
So far, Big Data is widely recognized as a positive advancement for science, as it enables more comprehensive studies and insights. However, it is crucial to approach it with a critical mindset and be mindful of the potential pitfalls and ethical concerns it brings about. My research shows that, while having vast amounts of data can be useful, it does not automatically ensure accurate and reliable results. Researchers must establish solid theoretical frameworks to ensure the scientific validity and interpretability of results derived from Big Data. Moreover, the use of personal data requires well-established regulations to balance the benefits of data utilization and the protection of individuals' privacy. As the volume and complexity of data continues to grow, it is becoming increasingly important to navigate these challenges responsibly and ethically.
This article was published in collaboration with MindMint.
More information
| Last modified: | 03 April 2024 10.49 a.m. |
More news
-
27 May 2024
Symposium 'From tensions to opportunities'
On 20 June 2024 a symposium will take place around the question: 'How to work effectively and meaningfully with internationalisation and diversity in study programs and disciplines?'. The symposium builds on the PhD research by Franka van den Hende...
-
22 May 2024
UG awards various prizes during the Ceremony of Merits
The UG awarded various prizes to excellent researchers and students during the Ceremony of Merits on 21 May 2024. The Wierenga-Rengerink PhD Award for the best UG dissertation was awarded to Dr Bram van Vulpen (Campus Fryslân). The Gratama Science...
-
29 January 2024
Sustainable behaviour? Information alone is not enough
As a social and environmental psychologist, Josefine Geiger looks into what motivates people to act in environmentally friendly ways. According to her, if we manage to overcome the barriers we sometimes perceive, an individual could have a lot of...