
What is voice AI? Inside Alexa, Siri, Google Assistant, and chatGPT
| Date: | 31 January 2025 |
| Author: | Matt Coler |

Voice AI transforms spoken words into digital actions. When you ask Siri about the weather or tell ChatGPT to write a story, you're using AI systems that can understand speech, process language, and respond in a human-like voice. But how do these digital assistants actually work?
Ever wondered why voice assistants instantly convert 'Play Ice Spice' into a Spotify search, but get confused when you say 'Play that viral song from TikTok'? With over 4 billion voice assistants now in use worldwide, these AI companions have become part of daily life - yet they can still be inconsistent. Today, we're peeling back the layers of technology that process your voice commands, revealing why they sometimes seem brilliant and other times... not so much.
From sound to signal: Voice detection
Voice assistants use specialized low-power processors that continuously digitize incoming audio through sampling - converting sound waves to digital signals thousands of times per second. These digital signals are then processed by neural networks trained to recognize specific wake word patterns (Hey Siri, Alexa, OK Google …), activating the main system only when detected.
To understand this, think of how effortlessly you can recognize your favorite jam (Ice Spice’s Boy’s a liar Pt. 2?) as soon as it starts playing -- almost from the first note. It’s easy to pick it out from the thousands of other songs that play on your Spotify playlist. The processor works similarly - it's highly efficient at one specific task: identifying the unique 'melody' of wake words like 'Hey Siri' or 'Alexa' from the constant stream of incoming sound.
Recognizing speech
Once activated, the system faces a more complex challenge: converting your full speech into text. After the wake word, you'll make a request - perhaps asking about the weather or setting a timer. This requires your iPhone to recognize your speech. This process is called Automatic Speech Recognition (ASR). It is like having a highly skilled transcriber who can adapt to any voice or situation.
Modern ASR systems achieve this flexibility through deep learning models trained on millions of voice samples. Think about how you can understand your friend speaking through a patchy phone connection, follow along with different accents, or even decipher a toddler's developing speech - ASR systems learn to handle these variations too (though not always reliably!). While they excel at widely-spoken languages like English or Mandarin, they often struggle with less-represented languages, regional dialects, and indigenous languages. For instance, there are over 7,000 languages spoken globally, but reliable ASR exists for a very small subset of those languages.
While they excel at widely-spoken languages like English or Mandarin, they [ASR systems] often struggle with less-represented languages, regional dialects, and indigenous languages.
Even within supported languages, performance varies significantly. Success depends on what data the algorithms have been trained on. A system might work well for “standard” American English but struggle with Scottish English or African American Vernacular English. People with speaking disfluencies, or who are language learners may also have some challenges being recognized reliably. As AI systems become more integrated into our daily lives, from job interviews to healthcare access, these limitations raise questions: Who gets to be understood by our machines, and what happens to those who don't?
The core of ASR capability lies in neural networks, which act like a sophisticated pattern-matching system. Just as you learned to recognize words by hearing them thousands of times in different contexts, these networks process layers of mathematical computations to map sound patterns to words. Each layer helps refine the understanding, from identifying basic sound units to assembling them into meaningful words and phrases.
In our MSc Speech Technology program, students work directly with these ASR systems, developing solutions for underrepresented languages and accents, contributing to novel solutions for people who need them.
Making sense of speech
Converting speech to text is just the beginning - imagine having a transcript but not understanding what it means. This is where Natural Language Processing (NLP) steps in, serving as the "brain" that interprets your commands and figures out what actions to take.
When you say "Set a timer for pasta and remind me to check the water in 10 minutes," the NLP system performs several sophisticated analyses:
-
Intent classification: First, it identifies that this single sentence contains two separate commands (setting a timer and creating a reminder).
-
Entity recognition: The system extracts key information:
-
Time duration: "10 minutes"
-
Task context: "pasta" and "check the water"
-
Action types: "set" (timer) and "remind" (notification)
-
-
Contextual understanding: The NLP must link these pieces together logically:
-
Associate "pasta" with the timer function
-
Connect "check the water" with the reminder
-
Understand that both actions are related to the same task
-
The challenge of context and ambiguity
Natural language is full of ambiguities that humans navigate effortlessly but challenge AI systems. Consider these variations of the same request:
-
"Timer for pasta, 10 minutes"
-
"Start cooking pasta and remind me about the water"
-
"Set a pasta timer and a water check reminder"
Each phrase means nearly the same thing, but expresses it differently. Modern NLP systems handle this through:
-
Semantic analysis: Understanding meaning beyond literal words. For instance, recognizing that "pasta timer" implies cooking, even when "cooking" isn't mentioned.
-
Pragmatic processing: Considering real-world context. The system knows that pasta cooking involves water and typically requires checking, helping it connect related commands logically.
From understanding to action
Once the NLP system has parsed your request, it creates a structured representation that the voice assistant can act on. Even if you've never seen code before, you can read this structured format (called JSON) like a recipe card - it simply lists out the actions to take, with each detail neatly organized:

This structured format ensures that complex requests are handled correctly and all parts of the command are executed in the right order with the proper relationships maintained.
Meantime, many are working on next-generation NLP systems that can handle even more complex scenarios:
-
Understanding implicit context: "It's getting late" → Should I set an alarm? Turn off lights? Both?
-
Managing multi-turn conversations: Remembering context from previous exchanges
-
Understanding that "dinner's ready" might mean pause a game, adjust the lights, and/or send a family notification depending on household patterns
These advances will make voice assistants feel more like natural conversation partners and less like command-driven interfaces.
Designing artificial speech
When a voice assistant needs to reply to you, it uses synthesis to create natural-sounding artificial speech. This process involves four steps:
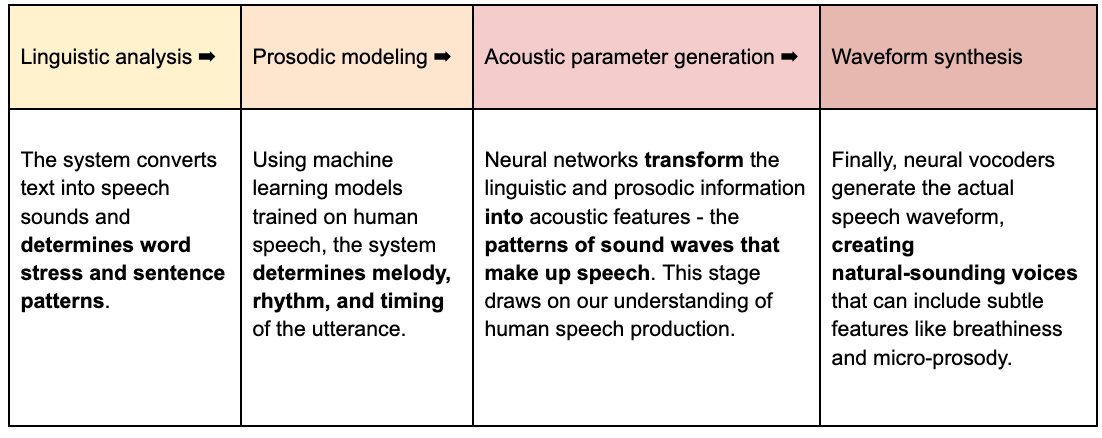
Speech synthesis represents a fascinating intersection of linguistics, signal processing, and artificial intelligence. Modern systems can produce remarkably natural speech, though achieving human-like expressiveness remains an active area of research.
Today's voice assistants have made synthetic speech part of daily life. Each has its own distinctive voice personality - from Alexa's warm, measured tones to Siri's crisp, professional delivery. These differences come from choices made during prosodic modeling and acoustic generation.
Yet you may notice these voices still sometimes sound unnatural, especially with complex emotions or longer responses. As language models like ChatGPT integrate with speech synthesis, creating voices that can engage in natural conversation becomes even more important.
Just as with speech recognition, synthesis technology works best for major languages with extensive data. While Siri supports around 20 languages with multiple accents, this represents only a very tiny fraction of the world's languages. This "speech technology gap" reflects broader issues of digital inequality. Creating natural-sounding synthesis for more languages remains both a technical challenge and an important goal for making voice technology truly accessible worldwide.
Our speech synthesis courses give students hands-on experience with neural vocoders and emotional speech generation. Some of our instructors will explore case studies around artificial voices that speak sarcastically, artificial voices that can speak very small languages, and more.
Advancing speech technology
The technology behind voice assistants continues to evolve, with exciting developments in multimodal interaction, emotional intelligence, and real-time translation. Future articles will explore these advances, along with critical discussions about privacy, ethics, and accessibility in speech technology.
The fact is, with generative AI and large language models like ChatGPT, we're entering an era of truly conversational AI. Future breakthroughs will emerge in:
-
Multimodal AI combining speech, vision, and text
-
Emotion-aware voice interfaces
-
Real-time multilingual communication
-
Voice preservation and restoration
The MSc Speech Technology program prepares you for this future. Through hands-on projects and research collaborations, you'll:
-
Build next-generation voice interfaces using generative AI
-
Develop inclusive speech technology for underserved communities
-
Create ethical AI systems that respect privacy and accessibility
-
Work with industry partners on real-world challenges
Join us in shaping how humanity interacts with AI!
- Sign up for our monhtly newsletter
- Visit our Speech Technology MSc programme webpage
- Already convinced? Apply now!
About the author

Matt Coler is an Associate Professor of Language & Technology at the University of Groningen (Campus Fryslân) where he is the Director of the MSc Speech Technology programme. Matt has performed extensive fieldwork in the Peruvian altiplano working on Aymara, Castellano Andino, and other Andean languages. He currently supervises several PhDs working on issues relating to under-resourced languages in Europe and beyond.
> View Matt's full profile